What's new in PHP 5.5
So, why another “PHP 5.5 new features” post? I was doing research on the subject for a tutorial at work so I was digging through all the resources I could find on the subject anyway, so I decided to write a post about it. And also because even though there are many great posts already on this topic, I found that none of them were that comprehensive to list all interesting changes that come with PHP 5.5. The PHP manual also has a quite comprehensive documentation about everything that has changed with PHP 5.5 here, but it is scattered across many pages with some not so relevant information (for most PHP devs) in there also. The official ChangeLog also lists everything that has changed, but it obviously does not go into that much detail on any of the topics.
Generators
I think the most discussed new feature has been generators. So, what generators actually are and what are they good for?
Generators look like normal functions or methods, except for the yield keyword. When calling yield the generator will return the given value to the caller but retain it’s state and continue where it left off when it is called next time. Generators also implement the Iterator interface, so they can be used with foreach loops for example. The usual examples given about generators are something like a replacement for PHP range() function or a Fibonacci number generator, I will not repeat them here (you can find these by reading some of the articles linked in this post), but instead present an equally useful example of a FizzBuzz implementation:
class FizzBuzz {
public function printValues($num = 100)
{
foreach ($this->getValues($num) as $value) {
echo $value . PHP_EOL;
}
}
private function getValues($num)
{
for ($i = 1; $i <= $num; $i++) {
$value = ($i % 3) ? '' : 'Fizz';
$value .= ($i % 5) ? '' : 'Buzz';
yield $value ?: $i;
}
}
}
$fb = new FizzBuzz();
$fb->printValues();
One thing to keep in mind is that the yield keyword does not work the same way as the return keyword. The return value of calling a generator is actually an object of a PHP internal class called Generator. The Generator class implements the Iterator interface as already stated above, so this means that if you want to get values from a generator outside of a foreach loop, you will have to manually call the current() and next() methods on it (as defined by the interface).
I suppose generators will be used mainly as iterators with foreach, where the generator will be called for each iteration and the yielded value will then be available in the loop, like in the example above. The main benefit of using generators like this is that if you have large set of data that you need to iterate over, you do not have to create one huge array to hold all the data but instead you can process it one piece at the time to keep memory usage under control. Situations like this could be processing some large data set from a database or a file to generate reports or graphs for example. Another use case would be if you do not initially know how many records you need to process, so you can only yield as many as you need and then break out of the loop. Generators can effectively be used to create infinite data sets (like the Fibonacci sequence), although I could not come up with any valid real world use case for it (apart from some advanced maths). Sebastian Bergmann also has written a blog post about using Generators as Data Providers with PHPUnit.
Generators also allow for two way communication between the calling code and the generator, i.e. you can send values back when the execution returns to the generator. This can be done by calling the send() method on the Generator instance. The sent value will be a “return” value of the yield expression. It is also possible to combine sending and receiving values within a generator with the same yield expression, but that could lead to some pretty hard to comprehend code quite easily. You can also throw exceptions into the generator in addition to throwing them from the generator. Throwing from the generator works as expected and the same way you normally throw an exception from a function or method. Throwing into the generator is done by calling the throw() method on the Generator object. You can then catch it inside the generator with a try-catch block around the yield.
Generators that you send data to can also be called coroutines, but that is a quite advanced topic and I will not cover it with anymore detail here, if you are interested to learn more about generators and coroutines, I suggest you read this post by Nikita Popov (developer of this feature in PHP core), the RFC of generators (also by Nikita Popov) and/or this post by Anthony Ferrara (also a PHP core contributor).
Password hashing API
With version 5.5 PHP finally has an easy to use and secure password hashing API, which is a big deal security wise. This allows people that are not very experienced with hashing and cryptography to securely store passwords without having to learn some complicated stuff about salts, cost, stretching etc. If you have already been storing passwords securely by either doing it with your own code, or by using some third party library, this means from now on you can use the simple PHP password hashing API and not have to do it yourself or add any dependencies to do it.
Generating a secure hash is as simple as this:
$hash = password_hash($password, PASSWORD_DEFAULT);
Under the hood the new password hashing API uses bcrypt for hashing and has automatic salting and also otherwise sane default values, so it is secure out of the box on most systems. There really is no reason to use any other hashing mechanism from now on in my opinion. Instead of using PASSWORD_DEFAULT, you can also specify the algorithm to use with PASSWORD_BCRYPT. Currently these are the only valid algorithms, but new ones will be added later as needed, and also the default algorithm may change in the future. An optional third parameter can also be used to provide some options for the hashing algorithm, such as salt and cost (for bcrypt). Note on the bcrypt cost parameter, it has a pretty good default value but it really is hardware dependent. So if you are worried about security, you should try what is a good cost value for your production hardware. An example script to do this can be found at the PHP manual page.
To verify if a password is valid when a user logs in, it is equally simple:
if (password_verify($password, $hash)) {
/* Valid password */
}
else {
/* Invalid password */
}
There is also a third function in this new API, called password_needs_rehash. This can be used to check if a password needs to be rehashed in case you have changed the options or hashing algorithm. With this functionality you can keep your software secure in the future as the hardware speeds increase you will eventually have to tweak the cost parameter, or change the algorithm entirely if a better one is introduced.
Here is an example of the usage:
if (password_needs_rehash($hash, $algorithm, $options)) {
/* Hash password with new algorithm or options */
/* Store the new hash */
}
If you are not yet ready to upgrade to PHP 5.5, but you like the new password hashing API and would like to use it in your application right now, there is a library that you can use for just this purpose called password_compat. It has the same API as the official PHP 5.5 implementation and it was created by the same developer as the PHP core implementation (Anthony Ferrara). This means that you can use it as long as your app is running with PHP version below 5.5, and when you upgrade to 5.5 it will start using the PHP core implementation automatically and you can remove the dependency to password_compat.
One thing to note is that if you use the PASSWORD_DEFAULT algorithm option, it is recommended to use VARCHAR(255) to store the hashes and not limit the size to current bcrypt hash size explicitly. This is to avoid issues in the future if the default algorithm is changed to something that creates longer hashes.
OPCache
PHP 5.5 has a built-in Opcode cache called OPcache. It is actually the previously called Zend Optimizer+ that was closed source software, but Zend open sourced it to be included in PHP core. An opcode cache increases performance of PHP applications with zero effort on the application side (by storing precompiled bytecode in shared memory so scripts will not have to be parsed on each request), i.e. you get faster app without doing anything. That is a no-brainer and also the reason you should be using an opcode cache even if you are still running some previous version of PHP. The OPcache extension can be installed as an extension to older PHP versions too, or you can of course use APC.
Even though OPcache is built-in with PHP 5.5 (compiled by default with PHP), it is not enabled by default so you will need to enable it. This can be done by simply editing the php.ini file as described in the manual. The way that different repositories for popular Linux distributions handle the installation/enabling this extension remains to be seen, it might be enabled by default or it might need to be enabled separately by installing some other package like php-opcache etc.
Performance wise the new Zend Optimizer+ has been a little bit better than APC. Here is a benchmark chart with PHP 5.5 without any opcode cache, with APC and with OPcache (generated from this chart that was linked in the RFC of OPcache)
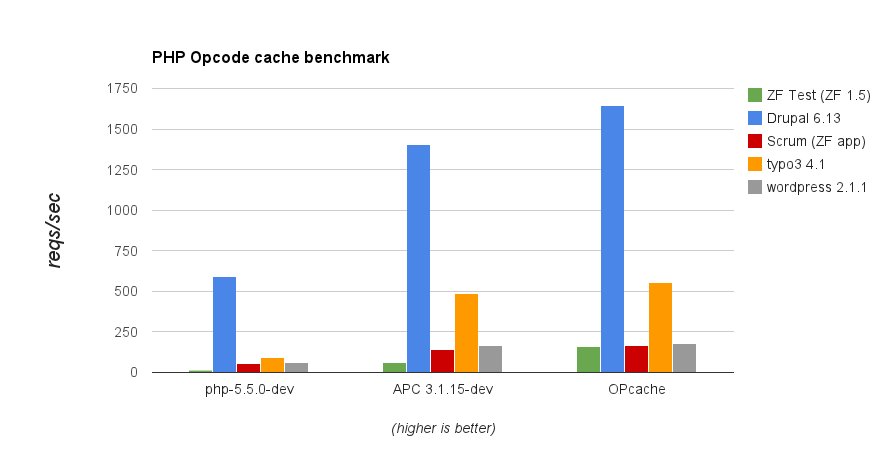
PHP Opcode cache benchmark
If you have been using APC’s data caching API you can use the APCu (short for APC user cache) that is a fork of APC with the opcode cache functionality removed. It is still in beta but a stable version should be available soon.
Something that you might need to consider when enabling OPcache is your deployment strategy. OPcache does not use inodes as keys in the shared memory (like APC), but instead it is realpath based. This means that if you override a file, it will start using the updated file immediately. This causes a situation where a running script might start execution on your old code base but start using files from a new code base in the middle of request if deployment happened at the same time. Whether or not you have to worry about situations like these depends on how much traffic your site/application has, how often you deploy, how critical the application is etc. so it’s really up to you to decide. This issue can be handled in many ways, Rasmus Lerdorf has posted a quite detailed description how they handle deploys atomically at Etsy by using a symlinked document root directory and a custom Apache module and PHP extension to resolve the symlink.
Finally
Finally there is… finally. The new finally keyword can be used with a try-catch block to execute certain code regardless if an exception was thrown or not. Actually you don’t even need the catch part, you can put finally after try if you are not anticipating any exceptions but want to make sure that some code is run even if an uncatched exception is thrown.
Here is a small example:
$db = mysqli_connect();
try {
//the function may throw exceptions which we can not handle
call_some_function($db);
} catch (SomeException $e) {
error($e);
} finally {
mysqli_close($db);
}
In the example above, the code inside the finally block will be called in all of these situations:
- The call to call_some_function() executes successfully without throwing any exceptions.
- An exception of type SomeException is thrown and catched and the code inside the catch block is executed.
- An uncaught exception is thrown.
So the finally is quite useful in case you need some code to execute regardless of what happens. The obvious use cases for this are things like cleanup, close resource handles like file pointers and external connections.
list() in foreach
Foreach now supports the use of list() that allows easier handling of nested arrays. Basically you can map the elements from the second level array into variables, all in the foreach statement itself.
Maybe an example will demonstrate this better, so here is a small script that iterates over some csv data:
$csvData = '1;Foo;bar
2;baz;
5;Lorem;ipsum';
foreach (parseCsv($csvData) as list($id, $name, $type)) {
echo 'Id: ' . $id . "\t"
. 'Name: ' . $name . "\t"
. 'Type: ' . $type . "\n";
}
function parseCsv($csv, $separator = ';')
{
foreach (explode("\n", $csv) as $csvLine) {
yield str_getcsv(trim($csvLine), $separator);
}
}
The output from this script would be:
Id: 1 Name: Foo Type: bar
Id: 2 Name: baz Type:
Id: 5 Name: Lorem Type: ipsum
The main use cases for this would be looping over nested arrays where the second level array always has the same known structure. So something like looping over SQL result sets or csv file data come to mind first. It doesn’t really matter where the data comes from, as long as it is in this kind of tabular format where you have any number of “rows” and each row contains same “columns”. You can then use this syntax to avoid using something like $row[1] that really has no meaning as to what data it holds.
empty(anything)
The empty() call (language construct, not a function) now supports arbitrary expressions, which means “just about anything you can throw at it” in more common terms, including function and method calls. Yay for this! No more “PHP Fatal error: Can’t use function return value in write context…”. It’s about time this finally works the way that everyone not knowing any better expects it to work.
Here are a few examples:
var_dump(empty("foo")); // false
var_dump(empty($foo)); // true
$bar = 1;
var_dump(empty($bar)); // false
var_dump(empty(--$bar)); // true
function foo() {
return 1;
}
var_dump(empty(foo())); // false
class Foo {
const CLASS_CONSTANT = true;
public function bar() {
return 0;
}
public static function baz() {
return null;
}
}
$foo = new Foo();
var_dump(empty($foo->bar())); // true
var_dump(empty(Foo::CLASS_CONSTANT)); // false
var_dump(empty(Foo::baz())); // true
var_dump(empty(function() { return -1; })); // false
$func = function() { return; };
var_dump(empty($func())); // true
$x = 1;
$y = 2;
var_dump(empty($x + $y)); // false
var_dump(empty(2 - 2)); // true
array_column()
The new array_column() function is a convenient way to get a single column of data from a multidimensional array. Similar to PDOStatement::fetchColumn() and what other database access layers provide for database record retrieval, array_column() can do the same in PHP. Nothing that special about it, you can do the same yourself quite easily, it’s just convenient to have it in the core and might be useful in many situations. You can also select what column you want to use as the index of the returned array by providing it as a third parameter.
Here is a small example:
$array = [
[
'id' => 2135,
'first_name' => 'John',
'last_name' => 'Doe'
],
[
'id' => 3245,
'first_name' => 'Sally',
'last_name' => 'Smith'
],
[
'id' => 5342,
'first_name' => 'Jane',
'last_name' => 'Jones'
],
];
$names = array_column($array, 'first_name');
print_r($names);
$namesById = array_column($array, 'last_name', 'id');
print_r($namesById);
And the output from that would be:
Array
(
[0] => John
[1] => Sally
[2] => Jane
)
Array
(
[2135] => Doe
[3245] => Smith
[5342] => Jones
)
The author of this function, Ben Ramsey, has also released a small userland library that you can use with previous versions of PHP if you can’t update right away but want to use it.
::class
A new ::class syntax allows the retrieval of the fully qualified class name of any namespaced classes that have been imported/aliased with a use statement.
Here is a simple example:
use Some\Really\Long\Namespacing\AndAlsoQuiteLongClassName as Foo;
echo 'Foo: ' . Foo::class;
And it will output:
Foo: Some\Really\Long\Namespacing\AndAlsoQuiteLongClassName
It is quite handy so you will not have to type (or copy-paste) the fully qualified class names around when you already have the class imported/aliased with a use statement.
The main use cases for this are any implementations where you have to provide a class name as a string. Some examples are PHPUnit’s mock builder, Doctrine entity manager, PHP’s built in reflection API and also with PHP functions such as class_exists() and is_subclass_of() etc. I think I will personally be using this most with the Doctrine entity manager since I am currently working with a Symfony project, and I am quite looking forward to using it since it is quite annoying to have to repeat the whole namespace every time like this: $this->em->getRepository('Acme\\DemoBundle\\Entity\\SomeEntity'); when you could just write $this->em->getRepository(Entity\SomeEntity::class); if you have a use statement like this: use Acme\DemoBundle\Entity;
The ::class syntax also works with other existing OOP keywords, such as self, static and parent, for example: self::class and parent::class. Although this does not provide any new functionality since you can get the equivalent of those in previous PHP versions with __CLASS__ and get_parent_class(), the new syntax is cleaner and more consistent so it’s a pretty nice thing in my opinion.
DateTimeImmutable
The new DateTimeImmutable class allows creating DateTime like objects that cannot be modified. This is mainly useful when using a single DateTime object multiple times, for example passing it as a parameter to other methods, performing calculations on it or displaying it in another timezone. Using DateTimeImmutable means you will not have to worry about whether the object has been changed somewhere along the way or not.
The DateTimeImmutable works almost just like regular DateTime, but there are a few gotchas. First one is that DateTimeImmutable does not inherit from DateTime so if you have a method that requires a DateTime object, you can not give it a DateTimeImmutable. The other thing is that, as stated before, DateTimeImmutable cannot be modified, but it returns a new object instead. The regular DateTime object returns $this to allow method chaining, but if you are not chaining anything you can just call a method to change the object, like for example $date->modify('+1 day'). With DateTimeImmutable you can also call it the same way but that will not change anything, you will have to assign the return value to a variable and that will be a new object and not the original, so the example would have to be changed to $date = $date->modify('+1 day').
Array and String Dereferencing
Constant array and string dereferencing, also known as constructor dereferencing and literal dereferencing, basically allows plucking one element from an array or one letter from a string right when creating the array or string. Again an example illustrates this better than any words I can come up with:
echo array('Foo', 'Bar', 'Baz')[1] . PHP_EOL; // Output: Bar
echo 'abc'[2] . PHP_EOL; // Output: c
You can of course use a variable at the referencing part (inside the brackets), which is kind of the only way this feature would make any sense. Although I still have a hard time coming up with any real world use cases for this. As I understand, the main reason behind implementing this feature was “because some other languages have it”. So I guess there are some use cases for this out there.
GD improvements
There are a few improvements to the GD image manipulation extension. Support for image flipping and cropping with functions imageflip(), imagecrop() and imagecropauto(). Support for reading and creating WebP images was also added with functions imagecreatefromwebp() and imagewebp().
Other misc new features/functions
Here is a list of some other miscellaneous new features and functions that I will not cover here with any more details.
- Non-scalar Iterator keys in foreach
- Apache 2.4 support on Windows
- boolval() - Get the boolean value of a variable
- cli_set_process_title() - Set PHP CLI process’ title that’s visible in top or ps
- hash_pbkdf2() - Generate a PBKDF2 key derivation of a supplied password
- CURLFile - cURL file upload class
- IntlCalendar
Deprecations and other removals
With all the great new stuff, also some old have been cleaned out. Here is a list of the most notable deprecations and removals:
- ext/mysql deprecated. This means that from now on when connecting to a database an E_DEPRECATED error will be generated. It can still be used for now, but it is advisable to use mysqli or PDO instead.
- Dropped Windows XP and 2003 support. Yea. Anybody still running modern PHP apps on those?
- preg_replace() /e modifier deprecated. preg_replace_callback() can be used instead.
- Logo GUIDs removed i.e. php_logo_guid() and zend_logo_guid()
I have tried to cover most of the relevant stuff here. You can check a more comprehensive list of all the little things that have changed at the PHP manual migration guide. Both new and removed.
Conclusion
PHP 5.5 has quite a lot of new and handy features and also a lot of nice little additions/modifications to existing features that make our lives as PHP developers a little bit easier. When doing the research about these new features for the tutorial and this blog post, I have come to the conclusion that the PHP RFCs (Request For Comments) is a really good place to learn about the new stuff. They often offer quite a lot of background about the changes or the new feature and almost always also give some real world use cases for them. Nikita Popov has put up a nice list of new features in PHP 5.5 that links to their respective RFCs. This has been really helpful and I have learned a lot when reading those. From now on I think I will always check the RFCs of the new features when a new version of PHP comes out.
This post turned out to be quite long, if you have read all the way here, hopefully you have learned something new. The next step is to try these out by yourself. I know I learned a lot by playing around with these new features. If you are familiar with Vagrant, you can have a virtual machine up and running with PHP 5.5 in just a few minutes, for example by using the awesome PuPHPet service where you can configure the VM on the website really easily.